
Weekly Readings 20241012
比预计更新的更晚了一些,计划没有变化快,突如其来的发了个烧,还没完全好。美团快检十分方便,上面取样送实验室检测之后是两种细菌感染,可能是着凉导致抵抗力弱吧,还得躺两天休息恢复。
十一假期去了趟东营,挺好的,印象最深刻的是到处都是油井,大锤头很帅。
育碧宣布重返 Steam,《刺客信条:影》及后续游戏都将首发同步登陆平台

9 月 27 日消息,育碧公司发言人确认,从《刺客信条:影》开始,育碧游戏将重返 Steam,该公司未来所有的新作将在发售当天同步上线 Steam。这也意味着育碧结束了与 Epic 的独家合作协议。
据悉,2019 年,育碧将《全境封锁 2》作为 Epic 游戏商城的独占游戏后迅速扩大了与 Epic 的合作。育碧高级副总裁 Chris Early 曾在同年 8 月公开批评 Steam 的商业模式,声称 Steam 平台 30% 的抽成“不可持续”,作为比较,Epic 平台仅收取 12%。
结合这一条《育碧股价下跌遭投资者施压,消息称已有 10% 股东支持私有化 / 出售公司》看就很有意思:「在过去 5 年,育碧股价下降了 80%,如今随着《星球大战:亡命之徒》等作遇冷,情况如今越来越糟。」
育碧现在的经营状况很大程度是自己作死的,十年前育碧推出的《刺客信条:大革命》虽然因为性能和 bug 的问题恶评如潮,但是它锐意创新,非常好玩,即使今天玩起来无论视觉效果还是游戏性仍然可以说是顶尖 3A 大作。但是在之后的年头里面明显开始吃老本,刺客信条变成清理问号的罐头游戏,每年换皮,其他 IP 也是类似,游戏不好玩,XGP 免费或者盗版都让人觉得下载是浪费时间的时候,这公司也就快完蛋了。
研究发现:AI 越聪明就越有可能“胡编乱造”
研究人员称,解决这些问题最简单的方法是让 LLM 不那么急于回答一切。Hernández-Orallo 称:“可以设置一个阈值,当问题具有挑战性时,让聊天机器人说‘不,我不知道’。”但如果聊天机器人被限制为只回答它们知道的东西,可能会暴露技术的局限性。
看到这个结尾的结论之后,感觉这研究人员根本就不知道自己在研究什么。如果能够通过程序判断答案置信度,那早就有这个阈值了。就是因为没办法判断才会一直胡言乱语啊。一个语言概率模型为什么能判断对错呢?
如果一个算法有能力基于自然语言的输入,判断真假、对错。那这个算法也算是有价值观了。
HIDDEN PREF TO RESTORE SLOW-MOTION DOCK MINIMIZING ON MACOS
In the midst of recording last week’s episode of The Talk Show with Nilay Patel, I offhandedly mentioned the age-old trick of holding down the Shift key while minimizing a window (clicking the yellow button) to see the genie effect in slow motion. Nilay was like “Wait, what? That’s not working for me...” and we moved on.
哈哈哈哈让我想起了刚用 macOS 的时候,好像也玩过这个,很好玩但是没什么用,新系统默认已经不能用了,想玩的朋友在终端里执行下面的命令开启
defaults write com.apple.dock slow-motion-allowed -bool YES; killall Dock
然后按住 Shift 键,最小化窗口就能看慢动作了。
The “it” in AI models is the dataset.
This is a surprising observation! It implies that model behavior is not determined by architecture, hyperparameters, or optimizer choices. It’s determined by your dataset, nothing else. Everything else is a means to an end in efficiently delivery compute to approximating that dataset.
今天看到的新闻《Nearly all of the Google images results for “baby peacock” are AI generated》让我想起了这篇文章。
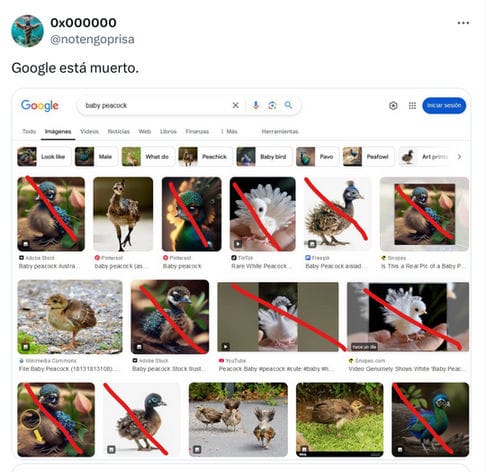
训练数据集对于现在的模型如此重要,以至于模型最好的结果也就是逼近数据集本身,那么当互联网上充斥这模型生成的垃圾内容的时候,模型会变成什么样呢?上个月的一条消息提到:用 AI 生成内容训练 AI 会导致模型崩溃,以后数据清洁师科学家可能会变成一个具有广泛就业空间的职业?